Part
I. Mining association rules from Human Development
Index dataset
1.
Dataset
description
The dataset consists of Human Development
Index (HDI) and statistics used for its calculations for 187 countries. HDI
assesses the standard of living in these countries. The dataset was extracted
from the following document which summarizes HDI statistics for year 2011: HDR_2011_EN_Table1.pdf. Here you can find
explanation of the attributes and how the HDI was calculated.
The dataset in csv format: HDI_data.csv. Open this dataset in WEKA explorer.
There are 187 transactions (countries) and 9 attributes
(items) in total. Obviously, we need to remove unique attributes such as country
name, since these are infrequent (occur only once). The remaining attributes
are numeric.
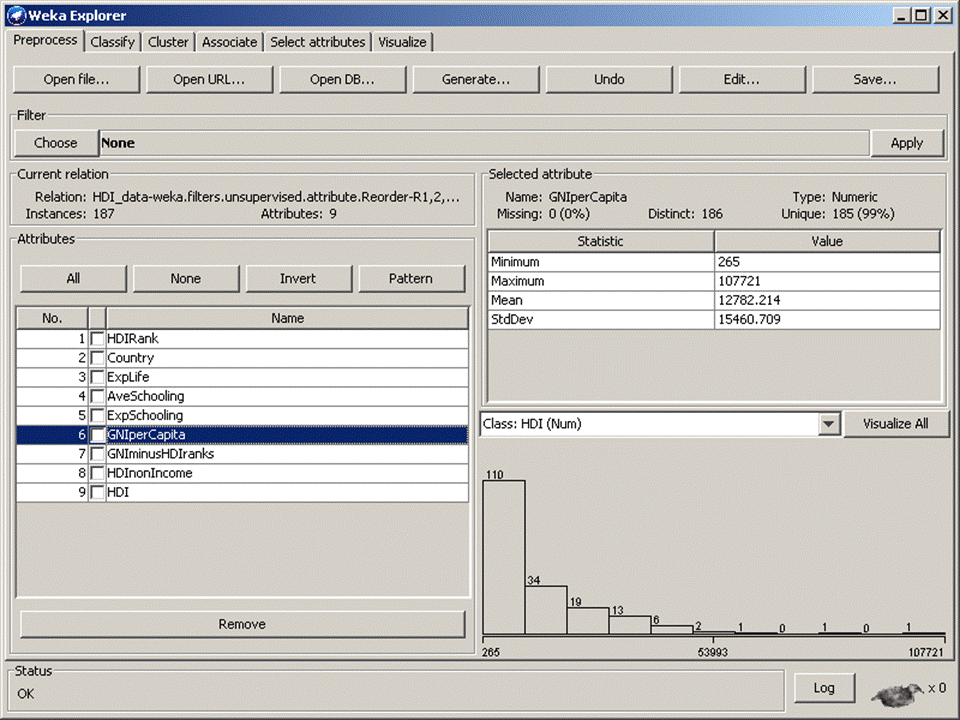
This dataset has the following complication: if you look at
the values of GNI per capita, you notice that these values vary from 265 to
107,721, however there are only 3 countries with GNI greater than 50,000
(exceptionally reach oil countries Singapore, Quatar
and United Arab Emirates).
If you discretize the values in
this column into 5 equal bins, almost all countries will be in the low GNI
category. This will artificially make the item ‘GNI=low’ very frequent. This in
turn will lead to spurious rules, where ‘Low GNI’ will be a part of every rule.
2.
Preprocessing
The first step is to remove unique attributes such as country
name. You may also remove the composite attributes such as HDI rank, HDI, and
HDI non income, but this is optional.
If you try to perform association analysis with the original
dataset, you will see that the start button on the Associate tab is disabled.
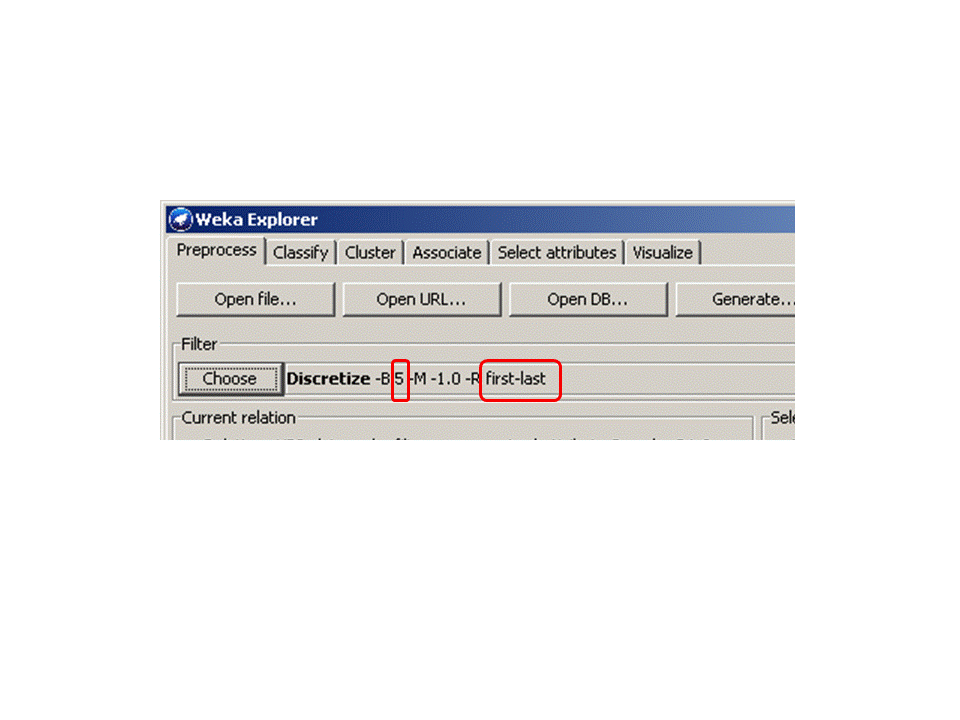
This is because to use association analysis in WEKA, we need to convert numeric
attributes into categorical. We will use
Filter->unsupervised->attribute->Discretize
with 5 bins for all the attributes.
3.
Default Apriori
On Associate tab, start Apriori
algorithm with default parameters. Examine the output.
4.
Problem
with equal-sized bins
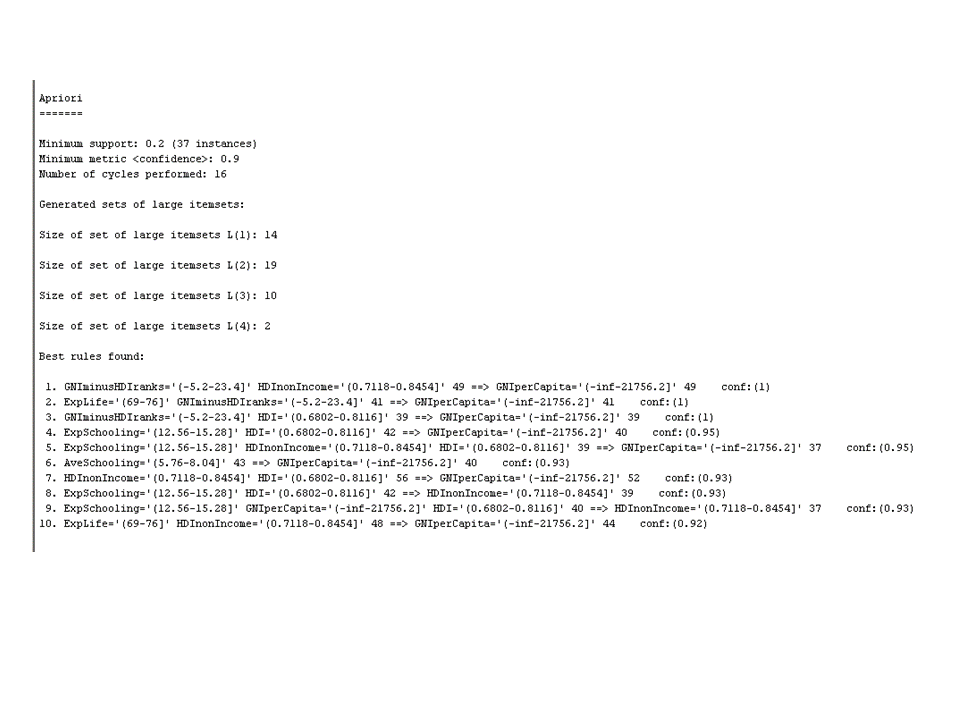
As expected, the item GNIperCapita='(-inf-21756.2]'
which corresponds to very low GNI is a part of almost every rule. This happens
because most countries fall into this category due to the fact that the mean
value for this attribute is about 12,000. These rules are spurious.
5.
Relabeling
intervals with java code
We will
preprocess the raw dataset using java code. Create new java project in eclipse.
Name it Lab7. Add the following java source file: NumericToIntervals.java. In order to
properly split numeric values into bins, we need to analyze values for each
attribute. We can do it in Excel, by computing min, max, interval and
delta=interval/5 values for each numeric column. The data analysis file is here.
Then, in our
java code, we will read each numeric value, replace it by the corresponding
interval, and give a meaningful label for each interval: one of {very low, low,
medium, high, very high}. For the GNIperCapita we
will divide the values into unequal bins: for column 6 we will use delta 5,000
instead of 21,491. Put the raw data file HDI_data.csv
into the project directory Lab7. Run the program. This will generate a new
re-labeled data file HDI_relabeled_bycode.csv.
We will use this data file as an input for the association analysis.
Load this
new file into WEKA. Remove attributes: Country, and optionally composite
attributes: HDIRank, HDI, HDInonIncome,
GNIminusHDIrank.
6.
Apriori parameters
Run again Apriori algorithm with
default parameters. Examine the output.
As expected, because of a high default min support threshold
10% the rules are quite trivial. Before running the Apriori
algorithm again, let us set the parameters: change parameters to: lowerBoundMinSupport: 0.05; min metric: 0.7; outputItemsets: true; number of rules: 50.
7.
Final
results
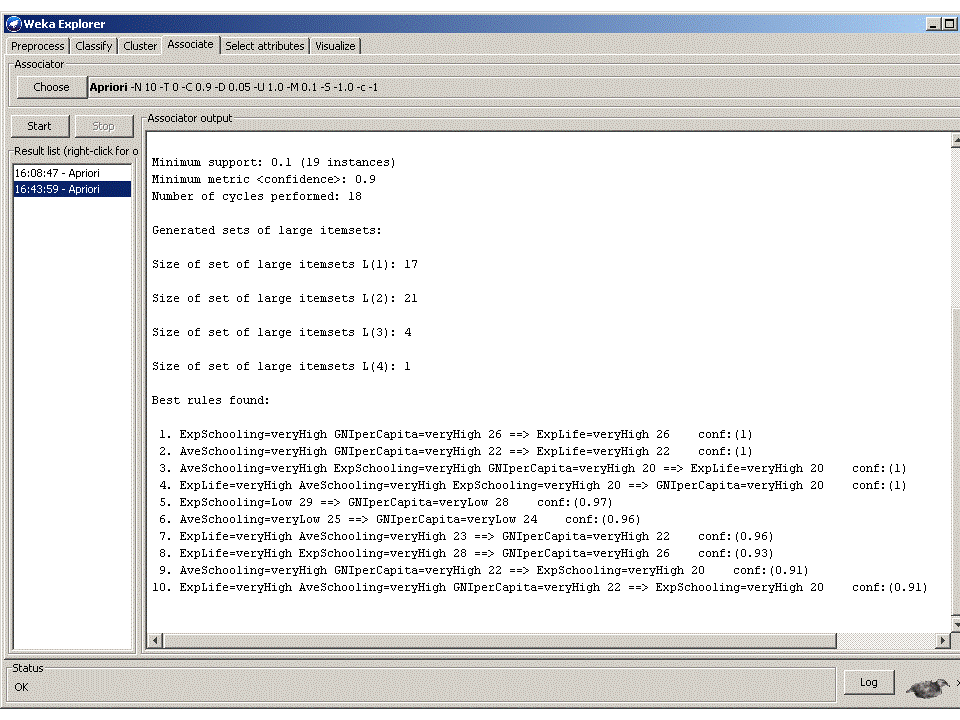
Run again.
In this run, we obtain 50 patterns and all frequent itemsets. Some of the rules are shown in the following
figure:
Among quite obvious patterns shown
in black, there are interesting patterns shown in blue,
and unexpected associations shown in red.
End of part
I
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}