Part
II. Association rules in a large dataset of transactions
1.
Dataset
description
Download the following dataset: marketbasket.csv.
This dataset contains the data from the point-of-sale transactions in a small supermarket.
Open the file in WEKA explorer.
The dataset consists of 1361 transactions. The total number
of distinct items is 255. All attributes are understood by WEKA as numeric. In
fact, they are all binary, having values either 0 (not purchased) or 1
(purchased). The first thing we need to do is to apply
Filter->unsupervised->attribute->NumericToNominal.
Select from the dropdown box of class attribute: no class option. If you do not select this option, then the class
attribute will be not converted into Nominal. Then click apply filter. Save the
resulting file in arff format as marketbasket.arff.
Now the dataset exactly corresponds to the binary input for
frequent pattern mining (as in the Pizza toppings dataset in slide 37 of our
first lecture about the Apriori algorithm). Though it
is tempting to try Apriori, do not attempt it in the
lab: it will cause memory overflow and WEKA will crash. You can try it at home,
where you know how to stop a non-responsive program, and how to recover from
the memory overflow.
In the previous lab, we applied Apriori
algorithm to categorical attributes with 5 different categories for each
attribute. Unlike Apriori algorithm, the FP-growth algorithm
takes as an input only binary format expressed as nominal attributes with 2
values: 0 and 1. This is exactly what we have, and now we can try the FP-growth
algorithm in Associate tab.
2.
FP-growth
with default parameters
Select FP-growth and run it with
default parameters. No rules found!
3.
Adjusting
parameters
Click on the
parameters line. Set lowerBoundMinSupport: 0.01; min
metric: 0.7. Start.
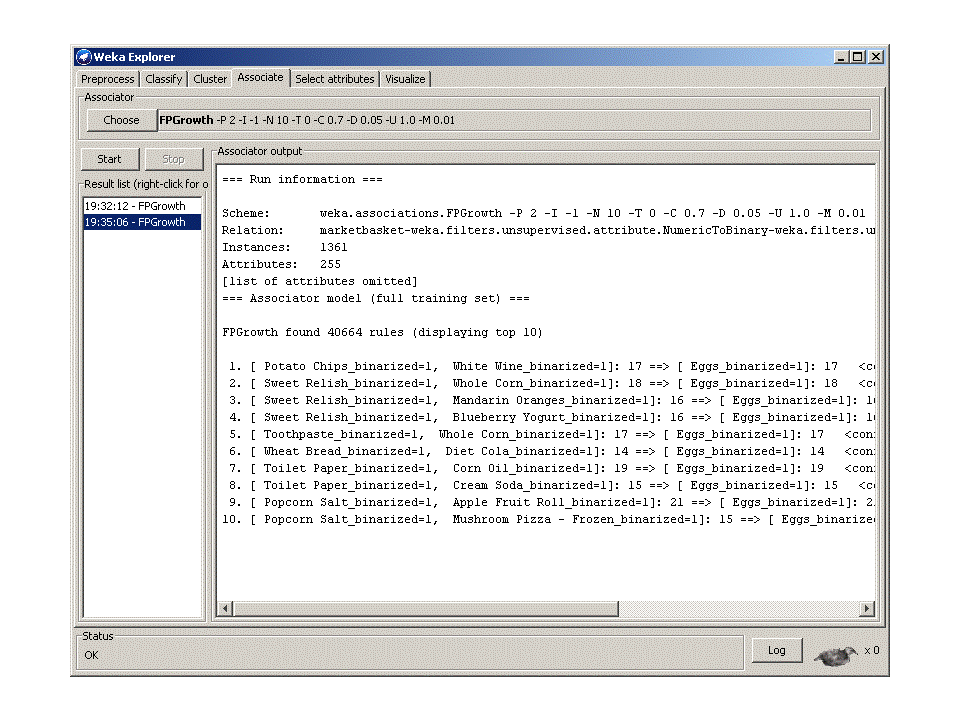
4.
Results
This time 40,664 rules were generated in several seconds.
This demonstrates the power of the FP-growth algorithm. The output:
End of Part
II
{kind=link}