Part
I. Discovering clusters in weather dataset
K-means
with default parameters
Get to the Weka
Explorer environment and load the training file weather.arff using the Preprocess mode. Get to the Cluster
mode (by clicking on the Cluster tab) and select a clustering algorithm,
for example SimpleKMeans. Then click on Start
and you get the clustering result in the output window. The actual clustering
for this algorithm is shown as one instance for each cluster representing the cluster
centroid.
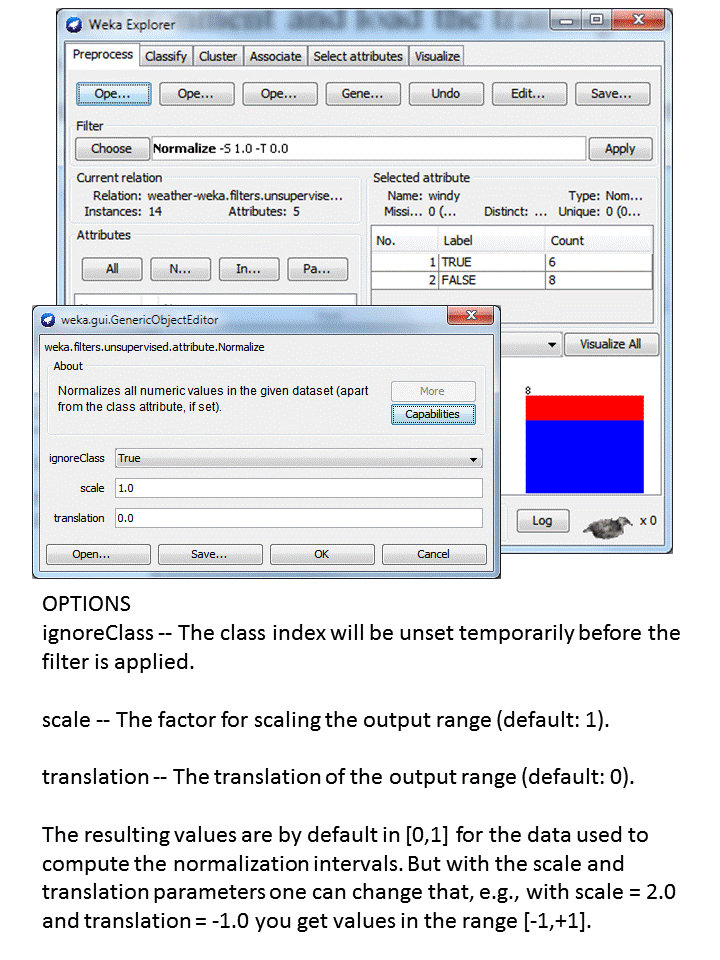
Normalization
You can
normalize all numeric values to the interval 0-1, by applying Filters ->
unsupervised -> normalize
Figure 2. Normalizing numeric
values
Evaluation
The way Weka
evaluates the clustering depends on the cluster mode you select. Different
evaluation modes are available (as buttons in the Cluster mode panel):
Hierarchical clustering
You can try a familiar agglomerative
hierarchical clustering algorithm in weka, by
choosing Hierarchical clusterer in Cluster tab.
However it is hard to interpret the output of this algorithm. The better output
is produced by Cobweb hierarchical clustering algorithm.
Cobweb
Cobweb generates hierarchical
clustering, where clusters are described probabilistically. Below is an example
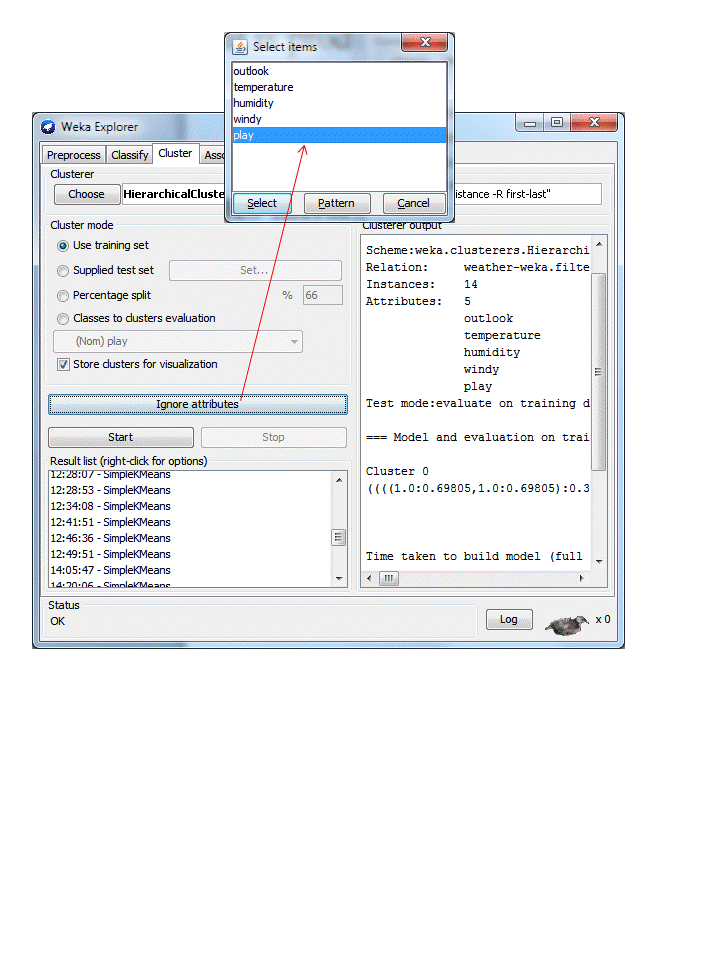
clustering of the weather data. The class attribute (play) is ignored (using
the ignore attributes panel – see how) in
order to allow later classes to clusters evaluation. Doing this automatically
through the "Classes to clusters" option does not make much sense for
hierarchical clustering, because of the large number of clusters. Sometimes we
need to evaluate particular clusters or levels in the clustering hierarchy. We
shall discuss here an approach to this.
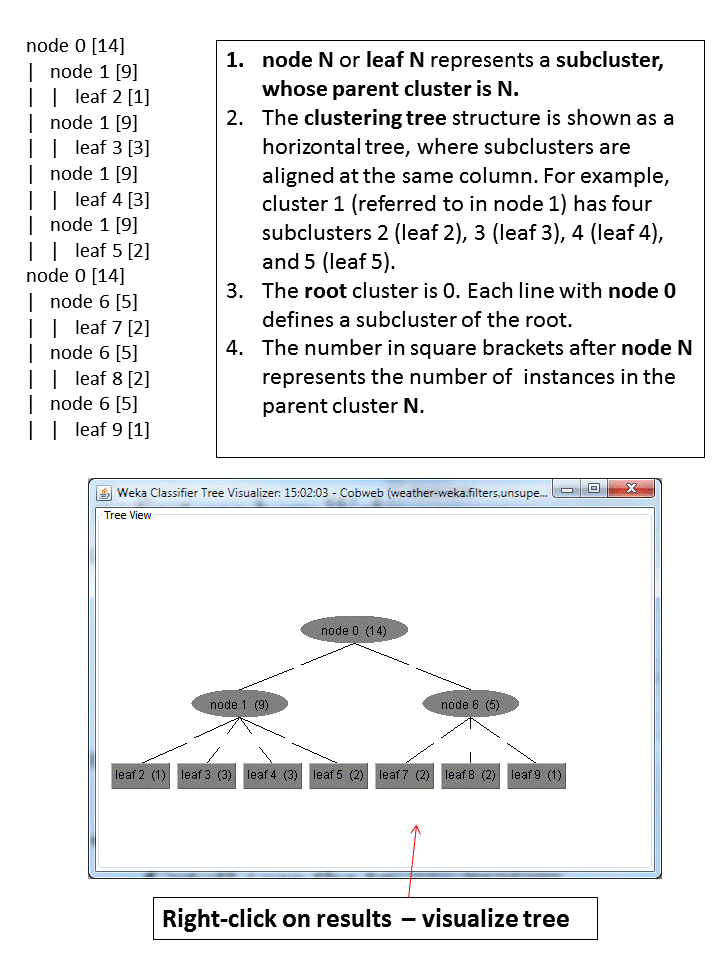
Let us first see how Weka represents the Cobweb clusters. Below is a copy
of the output window, showing the structure of the clustering tree.
Figure 4. Cobweb weather clusters
To evaluate the Cobweb
clustering using the classes to clusters
approach we need to know the class values of the instances, belonging to
the clusters. We can get this information from Weka
in the following way: After Weka finishes (with the
class attribute ignored), right click on the last line in the result
list window. Then choose Visualize cluster assignments - you get the
Weka cluster visualize window. Click on
Save and choose a file name (*.arff). Weka saves the cluster assignments in an ARFF file.
Below is shown the file corresponding to the above Cobweb clustering.
To represent the cluster assignments
Weka adds a new attribute Cluster and includes
its corresponding values at the end of each data line. Note that all other
attributes are shown, including the ignored ones (play, in this case). Also, only
the leaf clusters are shown.
Now, to compute the classes to
clusters error in, say, cluster 4 we look at the corresponding data
rows in the ARFF file and get the distribution of the class variable: {no, no,
yes}. This means that the majority class is no and the error is 1/3.
If we want to compute the error not
only for leaf clusters, we need to look at the clustering structure (the
Visualize tree option helps here) and determine how the leaf clusters are
combined in other clusters at higher levels of the hierarchy. For example, at
the top level we have two clusters - 1 and 6.
For cluster 1 we need its subclusters - 2, 3,
4, and 5. Summing up the class values we get 9 yes's and 2 no's.
Finally, the majority in cluster 1 is yes and the error (for
cluster 1) is 2/11.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}